Operational DB Migrations with Zero Downtime
Introduction
At Platformatory, we constantly work with customers whose operations demand round-the-clock availability and it is importat to maintain uninterrupted database access. They typically tend to scale their infrastructure, adopt new database technology, or making a strategic move to the cloud. So, ensuring zero downtime during database migration is critical.
For our customers (or for that matter anyone), downtime isn’t just an inconvenience—it could mean lost revenue, frustrated clients, and potential disruptions that ripple across their systems. In environments where even a minor outage could impact customer experiences or critical operations, ensuring seamless database migration becomes a key priority. A carefully planned zero-downtime migration allows them to evolve and scale your infrastructure while ensuring that the services remain fully operational.
Leveraging real-time data streaming and advanced synchronization techniques, our team ensures that data is continuously available while migrating databases behind the scenes. It’s about maintaining trust, keeping operations smooth, and continuing to deliver value to our clients without a hiccup. This post goes into the details of how such migrations can be orchestrated for a smooth transition by working through an example of migrating from SQL Server to MySQL (but, it can be done generically between two databases).
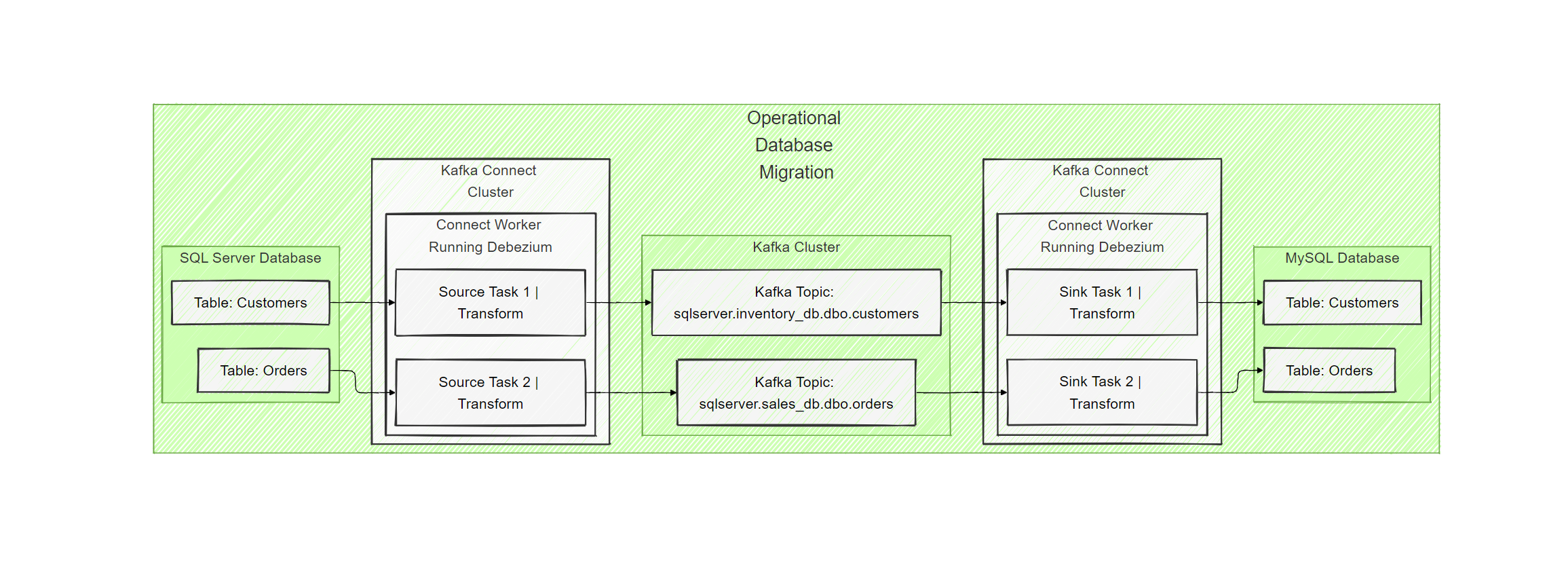
Migrating SQL Server Database to MySQL via Kafka Connect using Debezium
Let us quickly lay out the components that we will use for this. Apache Kafka is a distributed streaming platform used for building real-time data pipelines and streaming applications, enabling high-throughput, fault-tolerant data streams. Kafka Connect extends Kafka’s capabilities by integrating various data sources and sinks (destinations), while Debezium captures real-time database changes (CDC) and uses Single Message Transformations (SMT) to modify the streamed data before delivering it to Kafka topics.
Key Components:
- Kafka Topics: Each table from SQL Server streams data to a corresponding Kafka topic.
- Kafka Connect (Debezium): Captures the CDC events from SQL Server and pushes them into Kafka topics.
- Schema Registry: Ensures that data conforms to the defined schema before reaching MySQL.
- SMT (Single Message Transformations): Applied to transform the data (e.g., schema modifications, field renaming) before writing to MySQL.
- MySQL Sink Connector: Reads from Kafka topics and writes the transformed data into the MySQL database.
Detailed Migration Process
1. Initial Setup
- Set Up the Target MySQL Database
- Create the schema and tables in the target MySQL database to mirror the source SQL Server databases. Ensure the target schema is flexible to support the changes you’ll apply using SMT.
- Deploy Kafka and Kafka Connect
- Set up a Kafka cluster and deploy Kafka Connect. Kafka will be used to stream data from SQL Server databases to the target MySQL databases.
- Install the Debezium SQL Server Connector in Kafka Connect for CDC from SQL Server.
- Set up the Kafka Schema Registry to ensure the data schemas are enforced during transmission.
2. Configure Debezium for CDC
Debezium Connectors
-
For each SQL Server database, configure a Debezium connector to track changes (CDC). The connector will capture all insert, update, and delete operations in real-time from the transaction log of SQL Server databases and publish them to Kafka topics.
-
Example configuration for one database:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
{ "name": "sql-server-connector", "config": { "connector.class": "io.debezium.connector.sqlserver.SqlServerConnector", "database.hostname": "<sql-server-host>", "database.port": "1433", "database.user": "<username>", "database.password": "<password>", "database.dbname": "<db-name>", "database.server.name": "sql-server-source", "table.include.list": "schema.table", "snapshot.mode": "initial", "database.history.kafka.bootstrap.servers": "<kafka-brokers>", "database.history.kafka.topic": "dbhistory.sqlserver", "transforms": "unwrap", "transforms.unwrap.type": "io.debezium.transforms.UnwrapFromEnvelope", "transforms.unwrap.drop.tombstones": "false" } }
Kafka Topics
- Each SQL Server table will stream changes into separate Kafka topics. Kafka will act as the intermediary, ensuring that any change in the source databases is streamed in real-time to the target.
3. Applying Schema and Single Message Transformations (SMT)
Configure Schema Registry
- Use Kafka Schema Registry to enforce schemas for each table. This ensures that the data adheres to the expected format during the migration.
- Avro/JSON schema for the records will be managed through the registry.
Apply SMT for Data Transformation
- Use Kafka Single Message Transformations (SMT) to modify the records before they are written to MySQL. For example, you might want to rename fields, mask sensitive data, or change data types.
- Example SMT configuration:
1 2 3 4 5 6
{ "transforms": "InsertField", "transforms.InsertField.type": "org.apache.kafka.connect.transforms.InsertField$Value", "transforms.InsertField.static.field": "db_migrated", "transforms.InsertField.static.value": "true" }
Define Target Schema in MySQL
- The transformed records will fit into the target schema in MySQL. You can define specific rules in SMT to adjust field names or schemas as per the new structure.
4. Continuous Sync with Zero Downtime
Load Data
Initial Bulk Load
- Perform an initial bulk load of the data from SQL Server to MySQL using SQL tools or custom scripts to ensure the target database starts with a full copy of the data.
Incremental Data Load
Our preferred alternative to build load is a feature in Debezium called Incremental Snapshots with CDC. This is particularly useful for large tables or databases where a full snapshot is impractical due to size or operational constraints.
Debezium’s incremental snapshot feature enables the connector to:
- Capture data in smaller chunks.
- Continue capturing CDC events while the snapshot is being taken.
- Recover from failures and resume the snapshot from where it left off.
Benefits of Using Incremental Snapshots:
- Performance: Incremental snapshots reduce the overhead of taking a complete snapshot, especially for large datasets. The system captures data in chunks while streaming CDC events in parallel.
- Fault Tolerance: In case of errors during the snapshot process, Debezium can resume the snapshot without starting over.
- Reduced Load on the Source Database: By capturing data in smaller chunks, the load on the source database is minimized, and locks are held for shorter durations.
How to Configure Debezium for Incremental Snapshot and CDC Below is a Debezium SQL Server Source Connector configuration that enables incremental snapshots along with CDC. Configuration Example for Incremental Snapshot:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
{
"name": "sql-server-connector",
"config": {
"connector.class": "io.debezium.connector.sqlserver.SqlServerConnector", // SQL Server connector
"database.hostname": "your-sqlserver-hostname", // SQL Server host
"database.port": "1433", // SQL Server port (default: 1433)
"database.user": "your-username", // SQL Server username
"database.password": "your-password", // SQL Server password
"database.server.name": "sqlserver-source", // Logical server name
"database.dbname": "your-database-name", // Name of the SQL Server database
"database.history.kafka.bootstrap.servers": "your-kafka-brokers", // Kafka brokers for schema history
"database.history.kafka.topic": "schema-changes.sqlserver", // Kafka topic for schema changes
"table.include.list": "dbo.customers,dbo.orders", // List of tables for CDC and snapshot
// Configure initial snapshot and CDC
"snapshot.mode": "initial", // Take an initial snapshot (can be "initial" or "initial_only")
// Enabling incremental snapshot
"snapshot.fetch.size": "1000", // Fetch size for incremental snapshots (number of rows per batch)
// Incremental snapshot configuration
"incremental.snapshot.enabled": "true", // Enable incremental snapshot
"incremental.snapshot.chunk.size": "5000", // Size of the chunks for incremental snapshot (rows per chunk)
// CDC (Change Data Capture) settings
"database.encrypt": "false", // Disable encryption
"database.tcpKeepAlive": "true", // Keep TCP connection alive
// Kafka schema configuration
"include.schema.changes": "true", // Include schema change events in Kafka topics
"transforms": "unwrap,AddField", // Apply transformations
"transforms.unwrap.type": "io.debezium.transforms.UnwrapFromEnvelope", // Unwrap Debezium message envelope
"transforms.unwrap.drop.tombstones": "false", // Drop tombstone messages
"transforms.AddField.type": "org.apache.kafka.connect.transforms.InsertField$Value",
"transforms.AddField.static.field": "source_database",
"transforms.AddField.static.value": "${database.name}"
}
}
How Incremental Snapshot Works in Combination with CDC: Initial Snapshot: Debezium starts by taking an incremental snapshot of the specified tables. Instead of taking a full snapshot in one go, it splits the data into smaller chunks (e.g., 5000 rows per chunk). This makes the snapshot process more efficient and minimizes the load on the source database.
CDC in Parallel: While the snapshot is being taken, Debezium continues to monitor the transaction log for any changes. These CDC events are captured in real-time and sent to Kafka topics. This ensures that no changes are missed during the snapshot process.
Recovery from Failures: If an error occurs during the snapshot, Debezium can resume from where it left off, instead of starting the snapshot from scratch. This is particularly important for large datasets, where a full snapshot could take a long time.
Post-Snapshot: After the incremental snapshot is complete, Debezium continues to monitor CDC events only, as the snapshot has already captured the full historical data.
After this step, begin the real-time synchronization using Debezium.
Start Streaming CDC Data
- Kafka Connect with Debezium will start streaming the changes from the SQL Server databases to Kafka topics.
- The transformed records, as per the SMT rules, will be written into the MySQL database in real-time, ensuring that the two databases stay in sync.
Validation
- Continuously validate the data in MySQL to ensure consistency with the source SQL Server databases during the migration process.
5. Switchover to MySQL
Monitor and Verify
- Monitor the Kafka topics and connectors to ensure that any new changes in the source SQL Server databases are successfully replicated to MySQL.
Debezium Monitoring with Prometheus:
Debezium provides out-of-the-box metrics for monitoring the health of the CDC process. Metrics:
- debezium_task_state: The state of the Debezium tasks.
- debezium_task_errors: Number of errors encountered.
- debezium_task_latency: The latency of CDC events. Dashboard: Use Prometheus and Grafana to monitor Debezium’s task status, error rates, and event latency.
Data Integrity and Consistency Metrics
Some of the most important metrics to track to ensure that data integrity and consistency are maintained during the migration process:
-
Row Count Comparison: What it Measures: Compares the number of rows in each table in the source database and the target database after migration. Why it’s Important: A mismatch in row counts indicates that some records may not have been migrated, or duplicates may have been introduced. This is a basic but crucial integrity check. How to Monitor: Run Periodic Queries: Count the number of rows in critical tables in both the source and target databases, and compare the results. Dashboards: Display row count differences for each table, along with alerts for discrepancies.
-
Checksums or Hash Values:
What it Measures: Uses cryptographic hashes or checksums to ensure that the actual data values (not just row counts) are identical between the source and target databases. Why it’s Important: Even if row counts match, the actual data within those rows may differ due to data corruption, truncation, or transformation issues. How to Monitor:
- Hash Functions: Calculate a hash or checksum for key columns (or entire rows) in both the source and target databases.
- Comparison Logic: Compare the hash values between the two databases to detect any discrepancies. Dashboards: Show real-time comparison results, flagging any mismatches between source and target hashes.
Cutover Without Downtime
-
Once the target MySQL database is in sync and you’ve confirmed that all data has been migrated successfully, you can switch the application(s) to point to the MySQL database. In case there are microservices that write to the database, having a Blue/Green deployment with new database configuration will help in migration. In case Blue/Green deployment is not adopted, then a gradual rollout would be able to achieve the same.
-
Kafka will continue streaming changes during the switchover, ensuring zero downtime.
Conclusion
By leveraging Kafka, Debezium, Kafka Connect, SMT, and Schema Registry, you can achieve zero-downtime migration of 100 SQL Server databases to MySQL. This approach ensures that both systems remain in sync during the migration process while applying transformations to fit the new schema in MySQL.
About The Authors
About The Authors