Summary
- Introduction
- Need for Kafka Connect and Change Data Capture (CDC)
- Introduction to Oracle CDC Source Connector
- Redis Sink Connector
- Oracle DB Pre-requisite
- OS Pre-requisite
- Setting up Environment
- Oracle Docker Container Image
- Redis Kafka Connector
- Bring Up Confluent Platform using Docker Compose
- Oralce DB Configuration
- Connector Configuration
- Create Stream Processing using Ksqldb Query
- Testing Redis Sink Connector
- Clean up
- Conclusion
- Reference
Stream Oracle DB Changes to Redis with Confluent Platform: An End-to-End Guide
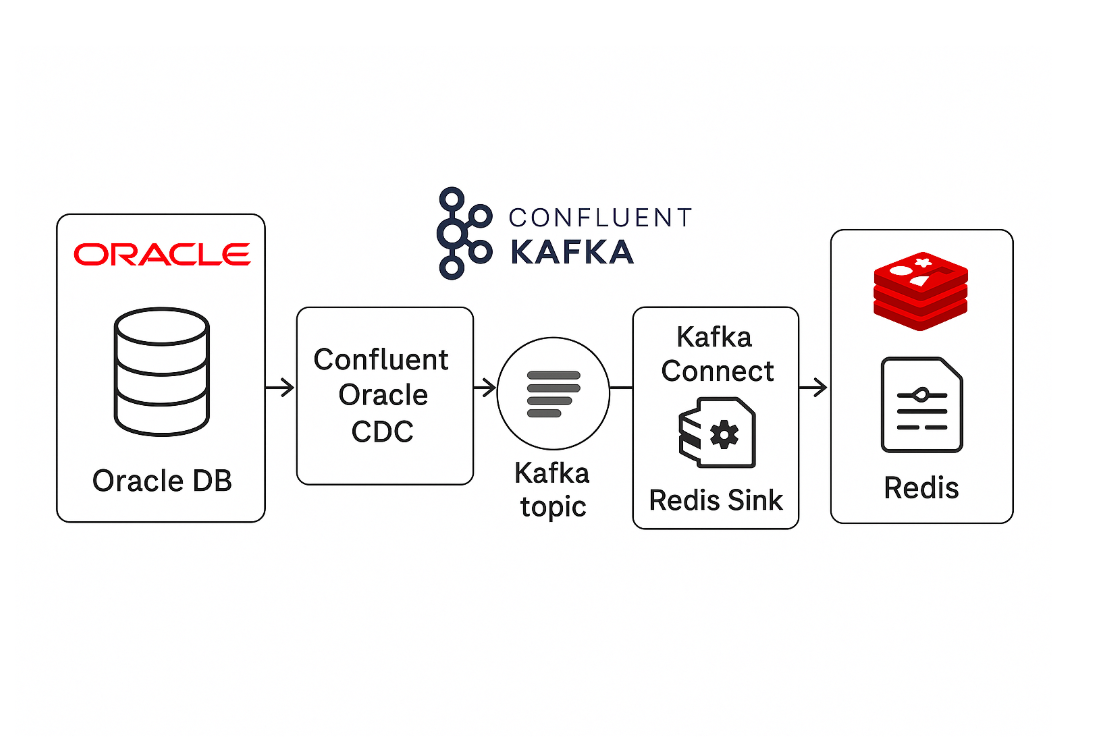
Introduction
Real-time data integration has become the backbone of modern data architectures, allowing businesses to react quickly to changing conditions and make informed decisions. One of the most powerful tools in this ecosystem is Change Data Capture (CDC), which enables organizations to monitor and capture changes in their databases as they occur. For businesses using Oracle Database as their primary data store, the Oracle CDC Source Connector for the Confluent Platform offers an easy and efficient way to stream database changes to Apache Kafka. This powerful combination allows for the creation of scalable, real-time data pipelines that can integrate, process, and analyze data with minimal latency. In this blog, we’ll walk through the capabilities of the Oracle CDC Source Connector, its key benefits, and how you can start using it to transform your data architecture.

Need for Kafka Connect and Change Data Capture (CDC)
Kafka Connect is a solution for streaming data between other data systems and Apache Kafka® with reliability. It facilitates the rapid definition of connections that transfer massive data sets into and out of Kafka. Kafka Connect can ingest whole databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing with low latency. Data from Kafka topics can be delivered via an export connector to batch systems, for offline analysis, or to secondary indexes, like Elasticsearch.
Data connection between databases, key-value stores, search indexes, and file systems is made easy with Kafka Connect, an Apache Kafka® component that is free and open-source. Kafka Connect allows you to quickly build connections that transfer big data sets into and out of Apache Kafka® and broadcast data between Apache Kafka® and other data systems.
You can use Oracle JDBC source connector to read data from Oracle DB, however this would capture only the snapshot of the table and not the changes or deleted rows. In the article, How to Integrate Your Database with Apache Kafka by Robin Moffatt, explores the distinction between log-based Change Data Capture (CDC) and a JDBC connector.
Introduction to Oracle CDC Source Connector
Oracle CDC Source Connector which records any modifications to database’s row, which is captured as change event records in Apache Kafka® topics. All tables that match an include regular expression and are accessible to the user can be included in the subset of tables that the connector can be set up to capture in a single database. A separate exclude regular expression can be set to prevent it from capturing tables that match those regular expressions. The connector uses Oracle LogMiner to read database redo log.
A subset of the tables in a single database, which is all tables that the user can access and that match an include regular expression, can be captured by the connector. Additionally, it can be set up to omit tables that match a different exclusion regular expression.

Redis Sink Connector
The Confluent Redis Kafka Connector makes it possible for Redis and Apache Kafka to integrate seamlessly and exchange data in real time. For use cases like caching, event sourcing, and analytics, it is perfect because it enables Kafka topics to transfer data to Redis. Compatibility with various data pipelines is guaranteed by its support for widely used serialization formats, including JSON, Avro, and Protobuf. The Redis Sink Connector allows for low-latency data access by streaming Kafka data to Redis. It is made to integrate easily with the Confluent Platform and offers scalability and stable setups for event-driven, real-time architectures.
One of the primary reasons for using a Redis Sink Connector is low-latency caching. Since Redis is an in-memory data store, it is well-suited for handling frequently accessed data with minimal latency. Streaming Kafka events into Redis ensures that applications can retrieve data almost instantly, making it ideal for use cases like recommendation engines, session storage, and leaderboards. Instead of relying on disk-based databases for quick lookups, Redis allows applications to access critical data in real time.
Another key advantage is real-time data processing. Kafka can ingest massive amounts of data, but consuming applications need immediate access to relevant information. By sinking Kafka data into Redis, applications can perform real-time aggregations, filtering, and analytics without the overhead of querying Kafka directly. This is particularly useful in scenarios like fraud detection, monitoring, and IoT telemetry, where events must be evaluated in milliseconds. Redis supports clustering and replication, making it a highly scalable and fault-tolerant data store for Kafka-driven applications. With a Redis Sink Connector continuously syncing Kafka data into Redis, applications can ensure real-time data availability without manual intervention or complex database queries.
In summary, a Redis Sink Connector is a vital component in real-time streaming architectures, bridging the gap between Kafka’s high-throughput messaging and Redis’s ultra-fast data access. It optimizes caching, enables instant analytics, and ensures that applications have quick access to processed event data. Whether for session management, caching, event enrichment, or real-time decision-making, integrating Redis with Kafka using a Sink Connector enhances performance and scalability in data-driven applications.

Oracle DB Pre-requisite
- Oracle Database versions 19c and later.
- Create a common user for a multitenant database. The username must start with “c##” or “C##
- Database must be enabled in ARCHIVEMODE
OS Pre-requisite
- Current user added into sudoers list
- Docker enging installed
Setting up Environment
Note: The following setup is executed on
Ubuntu 24.02 LTS
Oracle Source Connector
The Confluent Oracle CDC Source Connector comes under Premium Confluent Connector and requires additional subscription. Review the license at Confluent Oracle CDC Source Connector and download zip file. The zip file used in this setup is for Confluent Platform.
Unzip the confluentinc-kafka-connect-oracle-cdc-2.14.2.zip file.
NOTE – The version number may vary if newer version of source connector is available.
Oracle Docker Container Image
The docker image used for Oracle DB is heartu41/oracle19c. You can download the docker image using command:
1
$> docker pull heartu41/oracle19c
Redis Kafka Connector
The Redis Kafka Sink connector can be downloaded from Confluent Hub Page. You can also download directly by running command:
1
$> wget https://d2p6pa21dvn84.cloudfront.net/api/plugins/redis/redis-enterprise-kafka/versions/6.7.4/redis-redis-enterprise-kafka-6.7.4.zip
Unzip file redis-redis-enterprise-kafka-6.7.4.zip.
Bring Up Confluent Platform using Docker Compose
- Download or copy contents of [Docker Compose file] from Github repository for Confluent Platform Kraft all in one Docker Compose file.
1
$> wget https://d2p6pa21dvn84.cloudfront.net/api/plugins/redis/redis-enterprise-kafka/versions/6.7.4/redis-redis-enterprise-kafka-6.7.4.zip
- Open docker-compose.yml file in editor and add below sections:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
oracle-db:
image: heartu41/oracle19c
container_name: oracle
ports:
- "1521:1521"
environment:
ORACLE_PWD: "Oracle123"
ORACLE_SID: "ORCLCDB"
ENABLE_ARCHIVELOG: true
ENABLE_FORCE_LOGGING: true
volumes:
- ./oracleDB/oradata:/opt/oracle/oradata
redis:
image: redis/redis-stack-server
hostname: redis
container_name: redis
ports:
- "6379:6379"
- Update section “Connect” in docker-compose.yml file to include Oracle CDC source and Redis Sink connector.
1
2
3
4
5
6
7
8
depends_on:
- broker
- schema-registry
- redis
volumes:
- ./confluentinc-kafka-connect-oracle-cdc-2.14.2:/usr/share/java/confluentinc-kafka-connect-oracle-cdc-2.14.2
- ./redis-redis-kafka-connect-0.9.1:/usr/share/java/redis-redis-kafka-connect-0.9.1
- Save changes made in above steps in docker-compose file.
- Ensure Oracle CDC Connector and Redis Sink connector files are extraced
- Create a folder in current working directory where docker-compose.yml file is present along with Oracle CDC connector and Redis Sink Connector.
1
2
$> mkdir -p oracleDB/oradata
$> chown -R 54321:54321 oracleDB
- Start the Confluent Platform stack with the
-doption to run in detached mode.
1
$> docker compose up -d
Each component of docker compose file will start in a separate container. The output will look similar to:
1
2
3
4
5
6
7
8
9
10
Creating broker ... done
Creating schema-registry ... done
Creating rest-proxy ... done
Creating connect ... done
Creating ksqldb-server ... done
Creating control-center ... done
Creating ksql-datagen ... done
Creating ksqldb-cli ... done
Creating oracle-db ... done
Creating redis ... done
- Verify if all services are up and running.
1
$> docker compose ps -a
If any of the component isn’t up, you can start the individual container using command:
1
$> docker compose start <component name>
- The Oracle container when starting for the first time will take longer time to initialize itself. This will take approx. 15min- 25 mins depending upon the system configuration. Verify status of oracle container using command:
1
$> docker compose logs oracle
Wait till the oracle container is fully initialized with message “DATABASE IS READY TO USE!
Oralce DB Configuration
After the Oracle database is operational, we must configure it to activate ARCHIVELOG mode, add users, and set up the necessary permissions. Follow the steps mentioned below to setup required configuraiton on Oracle DB.
- Connect to Oracle container.
1
$> docker compose exec oracle bash
- Login to sql server:
1
$> sqlplus ‘/ as sysdba’
- Check if Oracle DB is in Archivelog mode. This is needed to extact Logminer dictionary to the redo logs.
1 2 3 4 5
SQL> select log_mode from v$database; LOG_MODE ------------ ARCHIVELOG
If log_mode is not in archivelog mode, run below commands to enable it.
1
2
3
4
SQL> SHUTDOWN IMMEDIATE;
SQL> STARTUP MOUNT;
SQL> ALTER DATABASE ARCHIVELOG;
SQL> ALTER DATABASE OPEN;
Check again for log_mode.
1
2
3
4
SQL> select log_mode from v$database;
LOG_MODE
------------
ARCHIVELOG
- Create role and grant required Access and permissions.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
CREATE ROLE C##CDC_PRIVS;
GRANT EXECUTE_CATALOG_ROLE TO C##CDC_PRIVS;
GRANT ALTER SESSION TO C##CDC_PRIVS;
GRANT SET CONTAINER TO C##CDC_PRIVS;
GRANT SELECT ANY TRANSACTION TO C##CDC_PRIVS;
GRANT SELECT ANY DICTIONARY TO C##CDC_PRIVS;
GRANT SELECT ON SYSTEM.LOGMNR_COL$ TO C##CDC_PRIVS;
GRANT SELECT ON SYSTEM.LOGMNR_OBJ$ TO C##CDC_PRIVS;
GRANT SELECT ON SYSTEM.LOGMNR_USER$ TO C##CDC_PRIVS;
GRANT SELECT ON SYSTEM.LOGMNR_UID$ TO C##CDC_PRIVS;
GRANT CREATE SESSION TO C##CDC_PRIVS;
GRANT EXECUTE ON SYS.DBMS_LOGMNR TO C##CDC_PRIVS;
GRANT LOGMINING TO C##CDC_PRIVS;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO C##CDC_PRIVS;
GRANT SELECT ON V_$DATABASE TO C##CDC_PRIVS;
GRANT SELECT ON V_$THREAD TO C##CDC_PRIVS;
GRANT SELECT ON V_$PARAMETER TO C##CDC_PRIVS;
GRANT SELECT ON V_$NLS_PARAMETERS TO C##CDC_PRIVS;
GRANT SELECT ON V_$TIMEZONE_NAMES TO C##CDC_PRIVS;
GRANT SELECT ON ALL_INDEXES TO C##CDC_PRIVS;
GRANT SELECT ON ALL_OBJECTS TO C##CDC_PRIVS;
GRANT SELECT ON ALL_USERS TO C##CDC_PRIVS;
GRANT SELECT ON ALL_CATALOG TO C##CDC_PRIVS;
GRANT SELECT ON ALL_CONSTRAINTS TO C##CDC_PRIVS;
GRANT SELECT ON ALL_CONS_COLUMNS TO C##CDC_PRIVS;
GRANT SELECT ON ALL_TAB_COLS TO C##CDC_PRIVS;
GRANT SELECT ON ALL_IND_COLUMNS TO C##CDC_PRIVS;
GRANT SELECT ON ALL_ENCRYPTED_COLUMNS TO C##CDC_PRIVS;
GRANT SELECT ON ALL_LOG_GROUPS TO C##CDC_PRIVS;
GRANT SELECT ON ALL_TAB_PARTITIONS TO C##CDC_PRIVS;
GRANT SELECT ON SYS.DBA_REGISTRY TO C##CDC_PRIVS;
GRANT SELECT ON SYS.OBJ$ TO C##CDC_PRIVS;
GRANT SELECT ON DBA_TABLESPACES TO C##CDC_PRIVS;
GRANT SELECT ON DBA_OBJECTS TO C##CDC_PRIVS;
GRANT SELECT ON SYS.ENC$ TO C##CDC_PRIVS;
GRANT SELECT ON V_$ARCHIVED_LOG TO C##CDC_PRIVS;
GRANT SELECT ON V_$LOG TO C##CDC_PRIVS;
GRANT SELECT ON V_$LOGFILE TO C##CDC_PRIVS;
GRANT SELECT ON V_$INSTANCE to C##CDC_PRIVS;
GRANT SELECT ANY TABLE TO C##CDC_PRIVS;
- Create user and grant required access. ``` CREATE USER C##MYUSER IDENTIFIED BY password DEFAULT TABLESPACE USERS CONTAINER=ALL;
ALTER USER C##MYUSER QUOTA UNLIMITED ON USERS; GRANT C##CDC_PRIVS to C##MYUSER CONTAINER=ALL; GRANT CONNECT TO C##MYUSER CONTAINER=ALL; GRANT CREATE TABLE TO C##MYUSER CONTAINER=ALL; GRANT CREATE SEQUENCE TO C##MYUSER CONTAINER=ALL; GRANT CREATE TRIGGER TO C##MYUSER CONTAINER=ALL; GRANT SELECT ON GV_$ARCHIVED_LOG TO C##MYUSER CONTAINER=ALL; GRANT SELECT ON GV_$DATABASE TO C##MYUSER CONTAINER=ALL; GRANT FLASHBACK ANY TABLE TO C##MYUSER; GRANT FLASHBACK ANY TABLE TO C##MYUSER container=all;
1
2
6. Create Userdata table and Clickstream table.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
CREATE TABLE C##MYUSER.POC_USERDATA (
ID VARCHAR2(50) PRIMARY KEY,
NAME VARCHAR2(50)
);
GRANT SELECT ON C##MYUSER.POC_USERDATA TO C##CDC_PRIVS;
INSERT INTO C##MYUSER.POC_USERDATA (ID, NAME)
VALUES ('101', 'jdoe' );
COMMIT;
CREATE TABLE C##MYUSER.POC_CLICKSTREAM (
EVENTID VARCHAR2(50) PRIMARY KEY,
ID VARCHAR2(50),
NAME VARCHAR2(50),
SESSIONID VARCHAR2(50),
EVENTTYPE VARCHAR2(50),
PAGEURL VARCHAR2(255),
EVENTTIMESTAMP TIMESTAMP
);
GRANT SELECT ON C##MYUSER.POC_CLICKSTREAM TO C##CDC_PRIVS;
INSERT INTO C##MYUSER.POC_CLICKSTREAM (EVENTID, ID, NAME, SESSIONID, EVENTTYPE, PAGEURL, EVENTTIMESTAMP)
VALUES (1, '101', 'jdoe', 'sess456', 'page_view', 'https://example.com/home', CURRENT_TIMESTAMP);
COMMIT; ```
Connector Configuration
Check if Oracle Source CDC Connector and Redis Sink connector is enabled and available.
1
$> curl -s -X GET -H 'Content-Type: application/json' http://localhost:8083/connector-plugins | jq '.'
The output should contain
- “class”: “io.confluent.connect.oracle.cdc.OracleCdcSourceConnector”
- “class”:”com.redis.kafka.connect.RedisSinkConnector”
This confirms the source and sink connector plugins are available with Kafka Connector.
Configure Oracle CDC Source Connector
Create Oracle CDC source connector configuration “userstream_source_connector.json” with content:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
{
"name": "userdata_avro",
"config":{
"connector.class": "io.confluent.connect.oracle.cdc.OracleCdcSourceConnector",
"name": "userdata_avro",
"tasks.max":1,
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"confluent.topic.bootstrap.servers":"broker:29092",
"oracle.server": "oracle",
"oracle.port": 1521,
"oracle.sid":"ORCLCDB",
"oracle.username": "C##MYUSER",
"oracle.password": "password",
"start.from":"snapshot",
"table.inclusion.regex":"ORCLCDB\\.C##MYUSER\\.POC_USER(.*)",
"table.exclusion.regex":"",
"table.topic.name.template": "${fullyQualifiedTableName}",
"connection.pool.max.size": 20,
"confluent.topic.replication.factor":1,
"redo.log.consumer.bootstrap.servers":"broker:29092",
"redo.log.corruption.topic": "redo-corruption-topic",
"topic.creation.groups": "redo",
"topic.creation.redo.include": "redo-log-topic",
"topic.creation.redo.replication.factor": 1,
"topic.creation.redo.partitions": 1,
"topic.creation.redo.cleanup.policy": "delete",
"topic.creation.redo.retention.ms": 1209600000,
"topic.creation.default.replication.factor": 1,
"topic.creation.default.partitions": 1,
"topic.creation.default.cleanup.policy": "delete",
"transforms": "dropExtraFields",
"transforms.dropExtraFields.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.dropExtraFields.blacklist": "scn, op_type, op_ts, current_ts, row_id, username"
}
}
Similarly create clickstream data source connector configuration json file clickstream_source_connector.json with contents:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
{
"name": "clickstream_avro",
"config":{
"connector.class": "io.confluent.connect.oracle.cdc.OracleCdcSourceConnector",
"name": "clickstream_avro",
"tasks.max":1,
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"confluent.topic.bootstrap.servers":"broker:29092",
"oracle.server": "oracle",
"oracle.port": 1521,
"oracle.sid":"ORCLCDB",
"oracle.username": "C##MYUSER",
"oracle.password": "password",
"start.from":"snapshot",
"table.inclusion.regex":"ORCLCDB\\.C##MYUSER\\.POC_CLICK(.*)",
"table.exclusion.regex":"",
"table.topic.name.template": "${fullyQualifiedTableName}",
"connection.pool.max.size": 20,
"confluent.topic.replication.factor":1,
"redo.log.consumer.bootstrap.servers":"broker:29092",
"redo.log.corruption.topic": "redo-corruption-topic",
"topic.creation.groups": "redo",
"topic.creation.redo.include": "redo-log-topic",
"topic.creation.redo.replication.factor": 1,
"topic.creation.redo.partitions": 1,
"topic.creation.redo.cleanup.policy": "delete",
"topic.creation.redo.retention.ms": 1209600000,
"topic.creation.default.replication.factor": 1,
"topic.creation.default.partitions": 1,
"topic.creation.default.cleanup.policy": "delete",
"transforms": "dropExtraFields",
"transforms.dropExtraFields.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.dropExtraFields.blacklist": "scn, op_type, op_ts, current_ts, row_id, username"
}
}
Configure Redis Sink Connector
Create Redis sink connector redis_sink.json using configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
{
"name": "redis-sink-json",
"config": {
"connector.class":"com.redis.kafka.connect.RedisSinkConnector",
"tasks.max":"1",
"topics":"USER_AGGREGATE_EVENTS",
"redis.uri":"redis://redis:6379",
"redis.command":"JSONSET",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"schemas.enable": "false"
}
}
Start connector based on the configuration created above
1
2
3
$> curl -s -X POST -H 'Content-Type: application/json' --data @userstream_source_connector.json http://localhost:8083/connectors | jq
$> curl -s -X POST -H 'Content-Type: application/json' --data @clickstream_source_connector.json http://localhost:8083/connectors | jq
$> curl -s -X POST -H 'Content-Type: application/json' --data @redis_sink.json http://localhost:8083/connectors | jq
Verify status of Source and Sink Connectors.
1
2
3
$> curl -s -X GET -H 'Content-Type: application/json' http://localhost:8083/connectors/userdata_avro/status | jq
$> curl -s -X GET -H 'Content-Type: application/json' http://localhost:8083/connectors/clickstream_avro/status | jq
$> curl -s -X GET -H 'Content-Type: application/json' http://localhost:8083/connectors/redis-sink-json/status | jq
With the userdata and clickstream source connector configured, the Oracle CDC source connector continuously monitors database, creating an event stream for any changes.
Create Stream Processing using Ksqldb Query
- Login to Confluent Control Center using http://
:9021 - Navigate to Cluster Overview → ksqlDB.
- In ksqlDB editor, set “auto.offset.reset”=”earliest” and enter below query to create Streams and Tables. Click “Run query” button to submit.
1 2 3 4 5 6 7 8
CREATE TABLE POC_USERDATA_STREAM ( ID STRING PRIMARY KEY, NAME STRING ) WITH ( KAFKA_TOPIC = 'ORCLCDB.C__MYUSER.POC_USERDATA', KEY_FORMAT = 'AVRO', VALUE_FORMAT = 'AVRO' );
1 2 3 4 5 6 7 8 9 10 11 12 13
CREATE STREAM POC_CLICKSTREAM_STREAM ( EVENTID STRING, ID STRING, NAME STRING, SESSIONID STRING, EVENTTYPE STRING, PAGEURL STRING, EVENTTIMESTAMP BIGINT ) WITH ( KAFKA_TOPIC = 'ORCLCDB.C__MYUSER.POC_CLICKSTREAM', KEY_FORMAT = 'AVRO', VALUE_FORMAT = 'AVRO' );
1
2
3
4
5
6
7
8
9
10
11
CREATE TABLE USER_AGGREGATE_EVENTS
WITH (
KEY_FORMAT = 'AVRO',
VALUE_FORMAT = 'AVRO'
) AS
SELECT
NAME,
COUNT(*) AS EVENT_COUNT
FROM POC_CLICKSTREAM_STREAM
WINDOW TUMBLING (SIZE 1 MINUTE)
GROUP BY NAME;
The Stream and Table created can be verified by navigating to ksqlDB –> Streams or ksqlDB –> Tables on Control Center GUI.
Userstream and Clickstream tables in Oracle DB must be updated in order to confirm that Oracle CDC Source Connector reads database changes. Connect to Oracle Container and update tables.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
$> docker compose exec oracle bash
$> sqlplus ‘/ as sysdba’
SQL> INSERT INTO C##MYUSER.POC_USERDATA (ID, NAME)
VALUES ('102', 'rsmith');
INSERT INTO C##MYUSER.POC_USERDATA (ID, NAME)
VALUES ('103', 'amary');
INSERT INTO C##MYUSER.POC_USERDATA (ID, NAME)
VALUES ('104', 'jwick');
INSERT INTO C##MYUSER.POC_USERDATA (ID, NAME)
VALUES ('105', 'jcena');
INSERT INTO C##MYUSER.POC_CLICKSTREAM (EVENTID, ID, NAME, SESSIONID, EVENTTYPE, PAGEURL, EVENTTIMESTAMP)
VALUES (2, '101', 'jdoe', 'sess456', 'click', 'https://example.com/product/123', CURRENT_TIMESTAMP);
INSERT INTO C##MYUSER.POC_CLICKSTREAM (EVENTID, ID, NAME, SESSIONID, EVENTTYPE, PAGEURL, EVENTTIMESTAMP)
VALUES (3, '101', 'jdoe', 'sess456', 'click', 'https://example.com/product/125', CURRENT_TIMESTAMP);
INSERT INTO C##MYUSER.POC_CLICKSTREAM (EVENTID, ID, NAME, SESSIONID, EVENTTYPE, PAGEURL, EVENTTIMESTAMP)
VALUES (4, '102', 'rsmith', 'sess789', 'click', 'https://example.com/about', CURRENT_TIMESTAMP);
INSERT INTO C##MYUSER.POC_CLICKSTREAM (EVENTID, ID, NAME, SESSIONID, EVENTTYPE, PAGEURL, EVENTTIMESTAMP)
VALUES (5, '102', 'rsmith', 'sess101', 'click', 'https://example.com/checkout', CURRENT_TIMESTAMP);
INSERT INTO C##MYUSER.POC_CLICKSTREAM (EVENTID, ID, NAME, SESSIONID, EVENTTYPE, PAGEURL, EVENTTIMESTAMP)
VALUES (6, '103', 'amary', 'sess101', 'click', 'https://example.com/checkout', CURRENT_TIMESTAMP);
INSERT INTO C##MYUSER.POC_CLICKSTREAM (EVENTID, ID, NAME, SESSIONID, EVENTTYPE, PAGEURL, EVENTTIMESTAMP)
VALUES (7, '103', 'amary', 'sess101', 'click', 'https://example.com/checkout', CURRENT_TIMESTAMP);
COMMIT;
The events added in the previous step create clickstream events and aggregate based on userid.
Testing Redis Sink Connector
The aggregated clickstream events can be verified in Redis since Redis Sink connector would read events from aggregated event table.
1
2
3
4
5
$> docker compose exec redis bash -c “redis-cli json.get USER_AGGREGATE_EVENTS:jdoe”
$> docker compose exec redis bash -c “redis-cli json.get USER_AGGREGATE_EVENTS:rsmith”
$> docker compose exec redis bash -c “redis-cli json.get USER_AGGREGATE_EVENTS:amary”
$> docker compose exec redis bash -c “redis-cli json.get USER_AGGREGATE_EVENTS:jwick”
$> docker compose exec redis bash -c “redis-cli json.get USER_AGGREGATE_EVENTS:jcena”
Clean up
To clean up your setup, you can run below command which will stop all running containers and remove any volumes used by container.
1
$> docker compose down -v
Conclusion
This showcases an end-to-end data streaming pipeline using the Confluent Platform, involving key components like the Kraft Controller, Kafka Broker, Kafka Connect with Oracle CDC Source and Redis Sink connectors, Schema Registry, ksqlDB, and Confluent Control Center. Data from two Oracle tables (Users and Clickstream) is captured using the Oracle CDC Source connector, published to Kafka topics in Avro format, and schemas are stored in the Schema Registry. A ksqlDB query processes the Clickstream data, aggregating clicks within a time window and sending the results to a new Kafka topic. Using the Redis Kafka Sink Connector, this processed data is then transferred to Redis. The Confluent Control Center is used to monitor the entire data flow, ensuring smooth operation from Oracle to Kafka to Redis.
Reference
About The Author
About The Author
